While machine learning provides us with a wide range of tools and resources to analyse the large complex datasets, systems biology - looking at the big picture - lends the biological context needed to infer and interpret the functional significance of the results.
Machine learning approaches can generally be classified into supervised and unsupervised models. Supervised methods use the sample labels to filter out features while unsupervised methods do not use sample labels. Machine learning methods also enable users not only to analyse singular data-types in isolation but to do it in an integrated manner.
For example, the recently published Multi Omics Factor Analysis (MOFA) based on a probabilistic Bayesian framework is tailored to capture hidden factors which capture the orthogonal variance in multiple data-types. The weights assigned to the samples (which can either be patient subjects or in-vitro specimens such as organoids) by such factors can be linked to binary or continuous variables representing the clinical phenotypes.
Systems biology approaches typically involve the use and integration of biological networks consisting of molecular interactions, -omic read outs and phenotypic information of the samples. They can be broadly classified as top-down data-driven approaches, bottom-up hypothesis driven approaches or a combination of the two.
Systems approaches can also be categorised as being qualitative or quantitative: the former representing methodologies which assign binary (present or absent; stimulatory or inhibitory, etc) relationships among variables (proteins, genes, etc), while the latter approach assigns magnitude (strength) to such relationships.
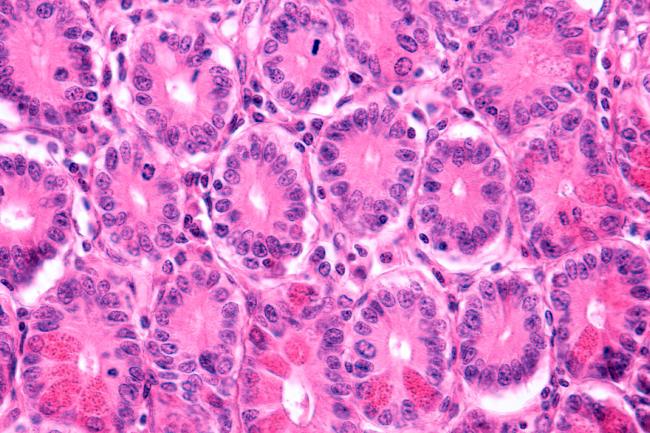
Generally, a common thread with systems biology approaches involves the use of quality-controlled biological networks which provide the biological and functional context to interpret the -omic datasets.